

컨텐츠 내용
- 수강신청
- 과정정보

과정소개

■ 과정명 : 예측 모델링, Vibe Coding과 AI 학습으로
■ 교육소개 : 본 과정은 SOA Exam PA(Predictive Analytics) 시험 대비 강의입니다. 예측 모델링의 핵심 개념을 이해하고, 시험에서 요구되는 R 코드 및 결과 해석 능력을 Google Colab에서 Gemini와 함께 R 코드를 작성·실행하는 Vibe Coding 실습으로 직접 익힙니다. 또한 Google NotebookLM을 활용해 방대한 학습 자료를 효율적으로 학습하는 방법과, 기출 시험을 AI로 분석·풀이하는 방법을 함께 다룹니다.
■ 교육일시 : 2026-07-09(목) ~ 10일(금) 13:00~18:00 (총 10시간 / 2일)
■ 교육장소 : 한국보험계리사회 세미나실 (주소: 서울시 종로구 새문안로3길 15, 동원빌딩 4층)
■ 수강대상 : 예측 분석 역량 강화 및 데이터 기반 의사결정에 관심 있는 모든 부서의 임직원, Google Colab, Gemini, NotebookLM 등 AI 학습/개발 도구를 활용해 효율적으로 학습하고 싶은 분
■ 사전지식 : Exam P, Exam SRM, VEE Mathematical Statistics
■ 준비물 : 노트북 필수 (Google Colab + Gemini로 R 코드 실습 진행), Google 무료 계정 (Colab, Gemini, NotebookLM 활용)
■ 강사소개 : 김현수 (뮌헨재보험 생명보험부 계리컨설팅 부장)
■ 이수학점 : 10학점
■ 문의처 : 전화 02-782-7440 (내선1번), 이메일 actuary@actuary.or.kr
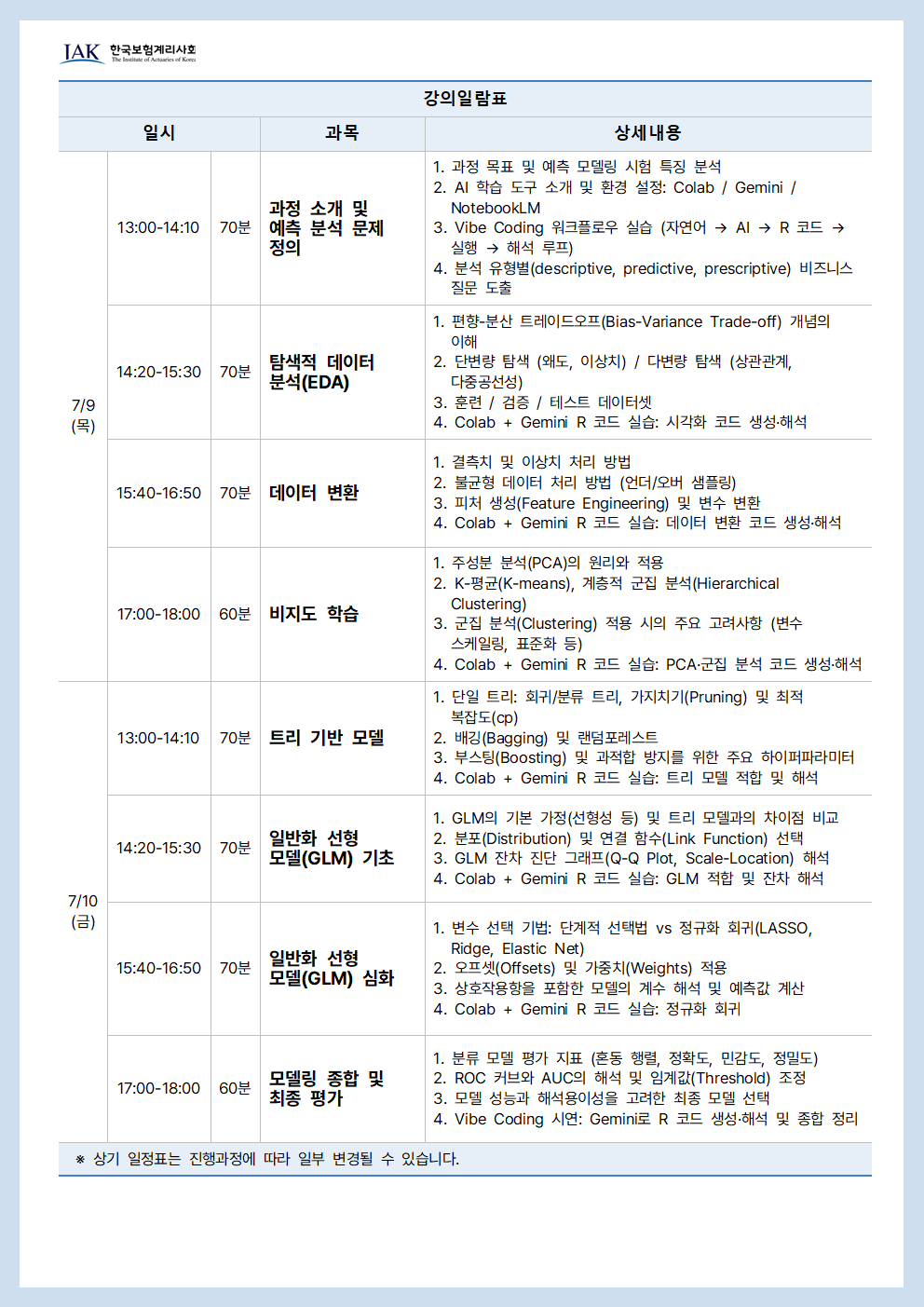
| 차시 | 일시 | 강의명 | 강의설명 |
|---|---|---|---|
| 1차시 | 2026.07.09 14:00~15:10 | 과정 소개 및 예측 분석 문제 정의 | 1. 과정 목표 및 PA exam 특징 분석 2. AI 기반 학습(NotebookLM) 활용법 소개 3. 분석 유형별(descriptive, predictive, prescriptive) 비즈니스 질문 도출 4. 편향-분산 트레이드오프(Bias-Variance Trade-off) 개념의 이해 |
| 2차시 | 2026.07.09 15:20~16:35 | 탐색적 데이터 분석(EDA) 및 데이터 변환 | 1. 데이터 분포(왜도, 이상치) 파악 및 데이터 처리와 정당화 2. 불균형 데이터의 문제점 파악 및 해결 방안 (언더/오버 샘플링) 3. 다중공선성(Multicollinearity) 문제 발견 및 해석 4. 기존 데이터로부터 모델 성능을 개선할 새로운 변수(피처) 생성 |
| 3차시 | 2026.07.09 16:45~18:00 | 트리 기반 모델 | 1. 불순도(Impurity) 및 엔트로피(Entropy) 개념 2. 단일 트리(Decision Trees)의 해석, 가지치기(Pruning) 및 최적 복잡도(cp) 선택 3. 배깅(Bagging), 랜덤포레스트 및 부스팅(Boosting) 4. 과적합(Overfitting) 방지를 위한 주요 하이퍼파라미터의 역할과 제어 방법 |
| 4차시 | 2026.07.09 14:00~15:10 | 비지도 학습 및 일반화 선형 모델(GLM) 기초 | 1. 주성분 분석(PCA), K-평균(K-means), 계층적 군집 분석(Hierarchical Clustering) 2. 군집 분석(Clustering) 적용 시의 주요 고려사항 (변수 스케일링, 표준화 등) 3. GLM의 기본 가정(선형성 등) 및 트리 모델과의 차이점 비교 4. GLM 잔차 진단 그래프(Q-Q Plot, Scale-Location) 해석 |
| 5차시 | 2026.07.09 15:20~16:35 | 일반화 선형 모델(GLM) 심화 | 1. 변수 선택 기법 비교: 단계적 선택법 vs 정규화 회귀(LASSO, Ridge) 2. GLM의 분포(Distribution) 및 연결 함수(Link Function) 선택 3. 오프셋(Offsets) 및 가중치(Weights) 적용 방법 4. 상호작용항을 포함한 모델의 계수 해석 및 예측값 계산 |
| 6차시 | 2026.07.09 16:45~18:00 | 모델링 종합 및 최종 평가 | 1. 분류 모델 평가 지표의 이해와 계산 (혼동 행렬, 정확도, 민감도, 정밀도) 2. ROC 커브와 AUC의 해석 및 비즈니스 목적에 따른 임계값(Threshold) 조정 3. 모델 성능과 해석용이성을 고려한 최종 모델 선택 및 정당화 4. AI 튜터를 활용한 개인별 학습 계획 및 약점 보완 |